
En 2017, unos investigadores de Google publican Attention is all you need, un paper de investigación que cambia por completo el campo de la inteligencia artificial (IA) y que introduce por primera vez el Transformer, un nuevo tipo de arquitectura de red neuronal.
El modelo Transformer ha revolucionado el procesamiento del lenguaje natural (NLP), demostrando ser muy eficaz en tareas de generación de contenido, como la creación de texto, música, imágenes, etc. La innovación clave de este nuevo modelo es el mecanismo de atención que emplea, el cual le permite centrarse en las partes de la secuencia de entrada que son más relevantes para generar la salida.
A continuación, se presenta una síntesis de los conceptos clave incluidos en el artículo Attention is all you need.
Introducción
Durante mucho tiempo, las redes neuronales recurrentes (RNNs) se han utilizado para el procesamiento de secuencias. Sin embargo, presentan algunas limitaciones, especialmente en cuanto a la forma en que realizan el procesamiento secuencial de la información de entrada.
Las RNNs procesan secuencias de datos en orden secuencial, lo que significa que cada paso debe esperar a que el anterior se complete. Esta manera de procesar la información limita la capacidad de paralelizar la ejecución de tareas. Esto se vuelve más importante cuanto mayor sea la longitud de la secuencia a procesar debido a las limitaciones de memoria, lo que termina afectado a la eficiencia del modelo.
Para abordar estos problemas, el Transformer se presenta como una nueva arquitectura que evita la recurrencia y que destaca por usar mecanismos de atención sobre todo el contexto, además de ofrecer una mayor capacidad para paralelizar tareas.
Contexto
Con el objetivo de reducir el cómputo que supone el procesamiento secuencial, existen modelos previos al Transformer como son Extended Neural GPU, ByteBet y ConvS2s, que utilizan redes neuronales convolucionales (CNN) para procesar datos en paralelo. Sin embargo, este tipo de modelos presentan problemas para procesar eficazmente la información cuando partes relacionadas de la secuencia de entrada se encuentran alejadas unas de otras, lo que se traduce en un incremento considerable en el número de operaciones a realizar, dificultando por tanto la velocidad de aprendizaje.
El Transformer pretende solucionar este problema, ya que siempre ejecuta una cantidad constante de operaciones independientemente de la distancia que exista entre las partes del texto. Para ello, hace uso del mecanismo de Auto-Atención (Self-Attention) para procesar secuencias de texto de forma más eficiente.
La Auto-Atención permite que el modelo de IA examine diferentes partes de la entrada (por ejemplo, diferentes palabras en una oración) y determine como de importantes son unas en relación con otras, para comprender el contexto completo. A través de este proceso, el modelo puede decidir a qué partes de la información prestar más atención y como estas partes se relacionan entre sí para formar un significado global.
Este proceso es clave, ya que el modelo, en lugar de tratar cada palabra o parte de la información por separado, es capaz de identificar como todas las palabras (tokens) se influyen y conectan entre sí a lo largo de la secuencia completa. Al hacer esto, el sistema puede entender mejor los textos complicados y realizar tareas como comprender preguntas y generar respuestas apropiadas.
Arquitectura
Muchas redes neuronales, entre ellas las que usan Transformers, se basan en una estructura codificador-descodificador:
- Codificador (Enconder): recibe una secuencia de símbolos como entrada. Para entenderla y prepararla para generar una salida, el codificador convierte cada símbolo de entrada en una serie de números (embeddings). Dicho de otra manera, es como si cada palabra o token de la secuencia de entrada fuera sustituida por un código que describe lo que significa y cómo se relaciona con las palabras que la rodean.
- Descodificador (Decoder): A partir de la información proporcionada por el codificador, comienza a generar la secuencia de salida. El modelo es auto-regresivo, lo que quiere decir que, para producir la secuencia de salida, el descodificador tiene en cuenta la última palabra que generó (o conjunto de ellas) para decidir cuál será la próxima.

Estructura
A continuación se muestra la estructura en capas del codificador y descodificador:

Codificador (enconder)
- Cada capa del codificador contiene dos subcapas principales:
- Subcapa de atención de múltiples cabezas (multi-head attention): Utiliza el mecanismo de atención autorregresiva para procesar la secuencia de entrada. Las múltiples heads permiten al modelo ejecutar varias funciones de atención de forma paralelizada.
- Subcapa de red neuronal de tipo feed-forward: Se compone de dos capas lineales con una activación no lineal entre ellas (usualmente ReLU o GELU).
Descodificador (decoder)
- Cada capa del decodificador tiene tres subcapas principales:
- Subcapa de atención de múltiples cabezas enmascarada (Masked Multi-Head Attention): Similar a la subcapa del codificador, pero se aplica un enmascaramiento para evitar que las posiciones futuras influyan en la predicción de una posición dada (esto es crucial durante el entrenamiento para mantener la naturaleza autorregresiva del decodificador).
- Subcapa de atención de múltiples cabezas (multi-head attention): Permite que el decodificador atienda a todas las posiciones de la secuencia de entrada. Las claves (keys) y los valores (values) provienen de la salida del codificador, mientras que las consultas (queries) vienen de la subcapa de atención previa del decodificador.a
- Subcapa de red neuronal de tipo feed-forward: Es idéntica a la que se encuentra en cada capa del codificador.
En resumen, cada capa del codificador y del decodificador en el modelo Transformer tiene una estructura de bloques con mecanismos de atención y redes neuronales feed-forward, todo conectado por conexiones residuales y normalización de capa para estabilizar el entrenamiento y permitir la construcción de modelos más profundos.
Atención
La función de atención (Self-Attention) permite a los modelos recordar y enfocarse en las partes relevantes de una secuencia de entrada para producir la mejor respuesta de salida. Imagina que quieres entender una pregunta y, para hacerlo, necesitas enfocarte en ciertas palabras clave para generar la respuesta; eso es, básicamente, lo que hace la función de atención.
Para generar la secuencia de salida, la función de atención calcula como de relevante es cada parte de la entrada para una determinada parte de la salida. Para ello, hace uso de una función de compatibilidad o puntuación. Cuanto más relevante sea un fragmento de información de la entrada, más peso tendrá.
La función de atención está compuesta de los siguientes elementos:
- Queries (Q): Es el elemento al que se quiere prestar atención. Se utilizan para que la función de atención pueda identificar información relevante en un conjunto de datos representados por claves (K) y valores (V).
- Keys (K): Funcionan como etiquetas que describen los values (V). La función de atención compara una query (Q) con cada key para determinar como de relevante es cada value con respecto a la consulta. En definitiva, las keys (K) se utilizan para guiar a la función de atención hacia los values más relevantes con el fin de generar la mejor respuesta de salida posible.
- Values (V): Contienen la información real que se quiere recuperar; son los datos que se entregan como respuesta basada en la relevancia determinada por las keys.

En resumen, cuando se utiliza la función de atención, lo que se hace es que las queries busquen a través de las keys para decidir qué values son más importantes y así concentrar la atención en esa información específica para generar una salida.
A continuación, se detallan los dos mecanismos propuestos para aplicar la función de atención: Scaled Dot-Product Attention y Multi-Head Attention.
Scaled Dot-Product Attention
Se trata de un mecanismo de atención fundamental en los modelos Transformer para conseguir prestar atención a las partes importantes de una secuencia.

Funciona de la siguiente manera:
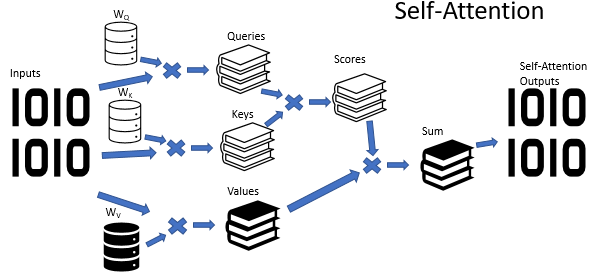
- Linealización: Se utilizan tres matrices de pesos llamadas Wq (queries), Wk (keys) y Wv (values) a la secuencia de entrada (X) para obtener los conjuntos de vectores de queries (Q), keys (K) y values (V) respectivamente.
- Puntuación: Se calcula un conjunto de puntuaciones de atención mediante la realización del producto escalar entre cada vector de consulta (Q) con todos los vectores de clave (K). Esto determina cuánta atención deberá prestar cada elemento de la secuencia a los demás elementos.
- Normalización: Como los valores pueden ser muy grandes y afectar el gradiente durante el entrenamiento, se normalizan los resultados del paso anterior, dividiéndolos por la raíz cuadrada de la dimensión del vector de keys (dk). Esto ayuda a mantener los valores estables y a evitar gradientes muy grandes o pequeños.
- Softmax: Esta función convierte las puntuaciones en probabilidades. Estas probabilidades determinan cuánta atención se debe prestar a cada value, siendo éstas entre 0 y 1.
- Ponderación de de valores: Se multiplican estas puntuaciones normalizadas con los vectores de valores (V) para ponderar su importancia en función de las puntuaciones de atención.
- Salida final: Para producir la salida final de la atención para cada query, se suman los valores ponderados. El resultado de todo este proceso es un conjunto de vectores, donde cada vector es una combinación de values basado en cuánta atención se decidió prestar a cada parte de la entrada.

Resumiendo, el algoritmo Self-Attention hace uso de 3 matrices entrenadas de los coeficientes de peso (Wq, Wk y Wv) para transformar la secuencia de entrada en vectores de consulta (Q), claves (K) y valores (V). La atención se calcula mediante un producto escalar entre consultas (Q) y claves (K), normalizado y aplicado a los valores (V) para obtener la salida que pondera la importancia relativa de las diferentes partes de la secuencia.
Multi-Head Attention
Este mecanismo, en lugar de invocar una única función de atención, ejecuta varias de ellas a la vez en diferentes hilos de ejecución, denominados heads (h).

La fórmula para calcular la atención es la siguiente:

Una vez aplicada la función de atención a cada head. se concatenan los resultados obtenidos en cada uno de ellos y se multiplican por la matriz de pesos de salida W0, cuyos parámetros se seleccionan durante el entrenamiento de la red neuronal, obteniendo así el resultado final.

Position-Wise Feed Forward (FNN)
Como se comentó anteriormente, en un modelo de tipo Tranformer, tanto el codificador como el descodificador, contienen una subcapa de tipo Multi Head Attention seguida por otra de tipo FNN (Feed-forward Neural Network).
Las redes neuronales de tipo Position-wise Feed-Forward son fundamentales para aumentar la capacidad y expresividad de los Transformers. Su propósito principal es transformar la representación intermedia proporcionado por la subcapa de Multi-Head Attention, permitiendo que el modelo aprenda más sobre las relaciones complejas entre diferentes palabras o elementos en una secuencia.
Embedding
Para manejar las palabras o tokens de entrada y salida, el modelo utiliza embeddings, que son representaciones vectoriales aprendidas de estos tokens. Cada palabra se convierte en un vector de una dimensión específica.

Función Softmax
La salida del descodificador (es decir, los vectores que representan las palabras o tokens) pasan por una transformación lineal y luego por una función softmax. La transformación lineal es básicamente una manera de preparar los datos antes de hacer predicciones, y la función softmax convierte esos datos preparados en probabilidades, indicando cuál es la probabilidad de que cada token sea el siguiente en la secuencia de salida.

En resumen, podemos decir que el modelo de procesamiento de lenguaje natural (NPL) transforma las palabras en representaciones matemáticas (embeddings) para realizar predicciones y poder identificar cual sería la siguiente palabra (token) más probable en una secuencia de salida, haciendo uso de un sistema eficiente y compartido de representaciones aprendidas.
¿Por qué es importante la Atención?
Hay varios motivos que justifican el uso de la función de atención en los modelos de procesamiento del lenguaje natural:
- Reducir la complejidad operacional en cada capa del modelo.
- Aumentar la capacidad de paralelización de las operaciones para reducir la secuencialidad y acelerar el procesamiento.
- Mejorar el manejo de dependencias de largo alcance (long-range dependencies) en una red neuronal, ya que, independientemente de la distancia que exista entre las distintas partes de un texto, siempre se realiza una cantidad constante de operaciones, lo que supone una mejora importante en términos de rendimiento.
En cuanto a los distintos tipos de arquitectura de redes neuronales, se destaca lo siguiente:
- Transformer: Todas las posiciones están conectadas entre sí con un número constante de operaciones secuenciales, lo cual es computacionalmente muy eficiente.
- Recurrentes (RNN): Requieren una cantidad de operaciones secuenciales proporcional al tamaño de la secuencia, lo que las hace menos eficientes para secuencias largas.
- Convolucionales (CNN): No conectan todas las posiciones de entrada y salida en una sola capa, sino que necesitan una pila de varias capas para hacerlo. Esto puede aumentar considerablemente la longitud de los caminos que las señales deben atravesar.
Conclusiones
En el artículo Attention is all you need, se presenta el Transformer como un nuevo modelo para la traducción de secuencia de datos, el cual hace uso de mecanismos de atención (Multi-Head Attention), lo que supone una mejora considerablemente de los resultados obtenidos con respecto a otras redes neuronales de tipo recurrentes (FNN) o convolucionales (CNN).
Una característica clave del Transformer es que puede aprender a hacer traducciones mucho más rápido que los modelos anteriores. Para ello, el modelo se entrenó originalmente para realizar tareas de traducción del inglés al alemán y del inglés al francés, superando a todos los sistemas anteriores en términos de velocidad y rendimiento.
El potencial de los modelos basados en mecanismos de atención es enorme, siendo aplicable no sólo a texto, sino a otros tipos de datos como imágenes, audio y video. Los autores del paper, como parte de su compromiso con la comunidad científica y tecnológica, han compartido el código fuente utilizado para entrenar y evaluar su modelo, el cual está disponible en este link.
Entre tú y yo
Reconozco que esta entrada ha sido larga y difícil de escribir. Intenté explicar los conceptos clave lo mejor que supe y de la forma más sencilla posible. La arquitectura del Transformer es compleja y requiere de mucho análisis para profundizar en ella. Por ello, si estás interesado, te animo a revisar el paper Attention is all you need así como otros links de interés que te dejo en el apartado de referencias.
Los Transformer es uno de los conceptos revolucionarios del deep learning que han cambiado la forma en que procesamos y generamos información. Espero que esta síntesis que he hecho del paper te haya resultado útil e interesante de leer.
Referencias
- Attention is all you need: https://arxiv.org/abs/1706.03762
- Código fuente entrenamiento y evaluación Transformer: https://github.com/tensorflow/tensor2tensor.
- Redes neuronales. Multi-head Attention: https://www.mql5.com/es/articles/8909
- Transformers: Attention is all you need: https://krypticmouse.hashnode.dev/attention-is-all-you-need
No responses yet